
吃瓜教程-p1
第一章 绪论
本章主要是对机器学习相关内容做了概述,通过西瓜外观判断瓜的质量的例子,将基本术语和假设空间的概念讲述清楚。
—————
数据集(关于西瓜数据的集合,例如【(色泽=青绿;根蒂=蜷缩;敲声=浊响),(色泽=乌黑;根蒂= 稍蜷;敲声=沉闷),(色泽=浅白;根蒂=硬挺;敲声=清脆),……)】
⬇️
示例/样本(特征向量)(关于一 个事件或对象(这里是一个西瓜)的描述)
⬇️
属性/特征(反映事件或对象在某方面的表现或性质的事项,例如“色泽”
“根蒂” “敲 声 )
⬇️
属性值(属性上的取值,例如“青绿”“乌黑”)
⬇️
属性空间/样本空间/输入空间(属性张成的空间,例如我们把“色泽” “根蒂” “敲声”作为三个坐标轴,则它们张成一个用于描述西瓜的三维空间,每个西瓜都可在这个空间中找到自己的坐标位置.由于空间中的每个点对应一个坐标向量,因此我们也把一个示例称为一个“特征向量”.)
—————
从数据中学得模型的过程称为“学习”(learning)或 “训练”(training), 这个过程通过执行某个学习算法来完成.训练过程中使用的数据称为“训练 数 据 “(training data), 其中每个样本称为一个“训练样本” (training sample), 训练样本组成的集合称为“训练集”(training set). 学得模型对应了关于数据 的某种潜在的规律,因此亦称“假设”(hypothesis); 这种潜在规律自身,则称 为 “ 真 相 ” 或 “ 真 实 ” , 学习过程就是为了找出或逼近真相 . 本书有时将模型称为 “ 学 习 器 ” , 可看作学习算法在给定数据和参数空间上的实例化 .
—————
标记
(色泽= 青绿;根蒂= 蜷缩; 敲声=浊响),好瓜),这里关于示例结果的信息,例 如 “好瓜”,称 为 “标 记”(label);拥有了标记信息的示例,则称为“样例”(example). 一般地,用(xi,hi)表示第i个样例,其中班G,是示例Xi的标记,J 是所有标记的集合, 亦称“标记空间”(label space)或“输出空间”.
聚类
将训练集中的样本分为若干组(簇),这些自动形成的簇存在一些潜在的概念划分.
—————
欲预测的是离散值———分类
###连续值———回归
训练数据有标记信息——-监督学习——分类、回归
###无标记信息——无监督学习—聚类
—————

机器学习的目标是使学得的模型能很好地适用于“新样本 “ 而不是仅仅在训练样本上工作得很好;即便对聚类这样的无监督学习任务,我们也希望学得的簇划分能适用于没在训练集中出现的样本.学得模型适用于 新样本 的能力,称为 “泛化 “(generalization)能力.具有强泛化能力的模型能很好地适用于整个样本空间.
—————
假设空间
有多个假设与训练集一致时,即存在着一个与训练集一致的“假设集合”,我们称之为“版本空间”.
—————
第二章 模型评估与选择

—————
把训练样本自身的一些特点当作了所有潜在样本都 会具有的一般性质,这样就会导致泛化性能下降.这种现象在机器学习中称为“过拟合” (overfitting).
与 “过拟合”相对的是“欠拟合” (imderRtting),这 是指对训练样本的一般性质尚未学好.
—————
评估方法
需使用一个“测试集”(testing set)来测试学习器对新样本的判别能力,然后以测试集上的“测试误差”(testing error)作为泛化误差的近似.测试样本尽量不在训练集中出现、未在训练过程中使用过.
—————
数据集的处理方法(当数据集有限但需要划分训练集T和测试集S时)
1.留出法
直接将数据集划分为两个互斥的集合,其中一个 集合作为训练集S,另一个作为测试集T,即0 =SUT,SnT=0.在S上训 练出模型后,用 T 来评估其测试误差,作为对泛化误差的估计.
需要注意(1)训练/测试集的划分要尽可能保持数据分布的一致性,(2)使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作 为留出法的评估结果。
此方法受训练集和测试集的划分比例影响较大。
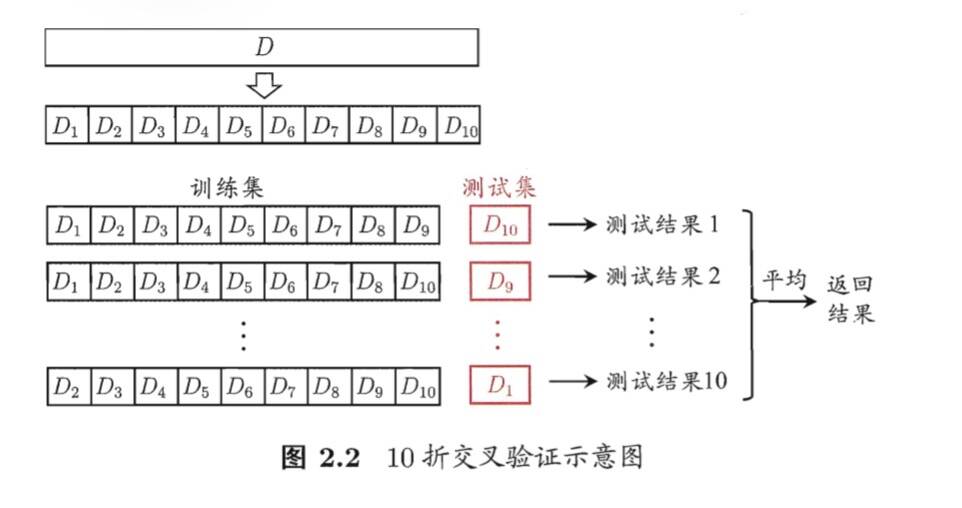
2.交叉验证法(k-fold)
将数据集 分层采样 划分为k个 大小相似 的互斥子集,将其中一个子集作为测试集,其余作为训练集,如此进行n次后取平均。
—————
交叉验证法评估结果的稳定性和保真性在很大程度上取决于k 的取值。
与留出法相似,将数据集。划分为k 个子集同样存在多种划分方式.为 减小因样本划分不同而引入的差别,k 折交叉验证通常要随机使用不同的划分 重复p 次,最终的评估结果是这p 次 k 折交叉验证结果的均值。
特例:留一法(k=数据集长度m,样本只有唯一的方式划分为m个子集,每个子集包含一个样本;留一法使用的训练集与初始数据集相比只少了一个样本,这就使得 在绝大多数情况下,留一法中被实际评估的模型与期望评估的用D 训练出的模 型很相似.因此,留一法的评估结果往往被认为比较准确.缺陷:在数据集比较大时,训练M 个模型的计算开销难以忍受,且准确度不一定高)
3.自助法
给定包含 m 个样 本的数据集。,我们对它进行采样产生数据集每次随机从。中挑选一个 样本,将其拷贝放入少 ,然后再将该样本放回初始数据集D 中,使得该样本在 下次采样时仍有可能被采到;这个过程重复执行m 次后,我们就得到了包含m 个样本的数据集D,这就是自助采样的结果.
估计,样本在m次采样中始终不被采到的概率取极限约为0.368,实际评估的模型与 期望评估的模型都使用馆个训练样本,而我们仍有数据总量约1 / 3 的、没在训 练集中出现的样本用于测试.这样的测试结果,亦 称 “包外估计”.
自助法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法 能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处. 然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差.在初始数据量足够时,留出法和交叉验证法更常用一些.
4.调参
大多数学习算法都有些参数(parameter)需要设定,参数配置不同,学得模 型的性能往往有显著差别.因此,在进行模型评估与选择时,除了要对适用学习 算法进行选择,还需对算法参数进行设定,这就是通常所说的“参数调节”或 简 称 “调 参 “
参数调得好不好往往对最终模型性能有关键性影响.
—————
性能度量
衡量模型泛化能力的评价标准,这就是性能度量
性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往 往会导致不同的评判结果;这意味着模型的“好坏”是相对的,什么样的模型 是好的,不仅取决于算法和数据,还决定于任务需求.
1.错误率和精度:分类任务中最常用的两种性能度量, 既适用于二分类任务,也适用于多分类任务

2.查准率、查全率与F1
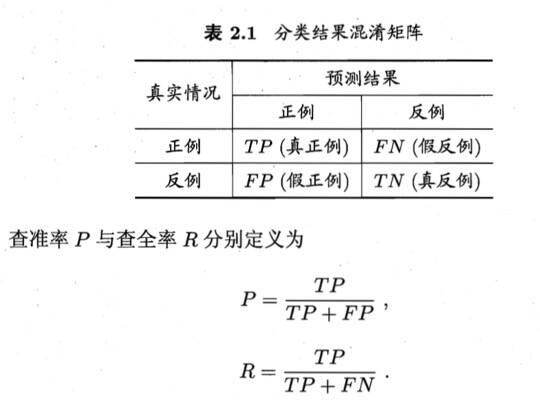
根据学习器的预测结果对样例进行排序,排在前面 的是学习器认为“最可能”是正例的样本,排在最后的则是学习器认为“最 不可能”是正例的样本.按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查全率、查准率.以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲计算出当前的查全率、查准率.以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称“P-R曲线〃,显示该曲线的图称为“P-R图”.
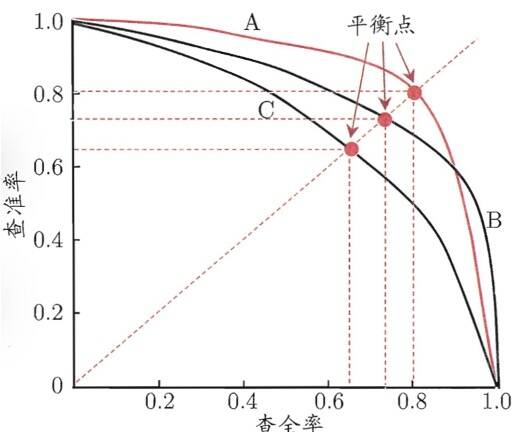
若一个学习器的P - R 曲线被另一个学习器的曲线完全“包住”,则可断言 后者的性能优于前者
当出现交叉时,有两种性能度量:
1.平衡点(BEP)它是“查准率 = 查全率,时的取值。
2.F1度量

其中B > 0度量了查全率对查准率的相对重要性[VanRijsbergen, 1979].
B = 1 时退化为标准的F1;^ > 1时查全率有更大影响;B< 1时查准率有更大影响.
很多时候我们有多个二分类混淆矩阵,例如进行多次训练/测试,每次得到 一个混淆矩阵;或是在多个数据集上进行训练/测试,希望估计算法的“全局” 性能;甚或是执行多分类任务,每两两类别的组合都对应一个混淆矩阵;•…・ 总之,我们希望在n 个二分类混淆矩阵上综合考察查准率和查全率.



