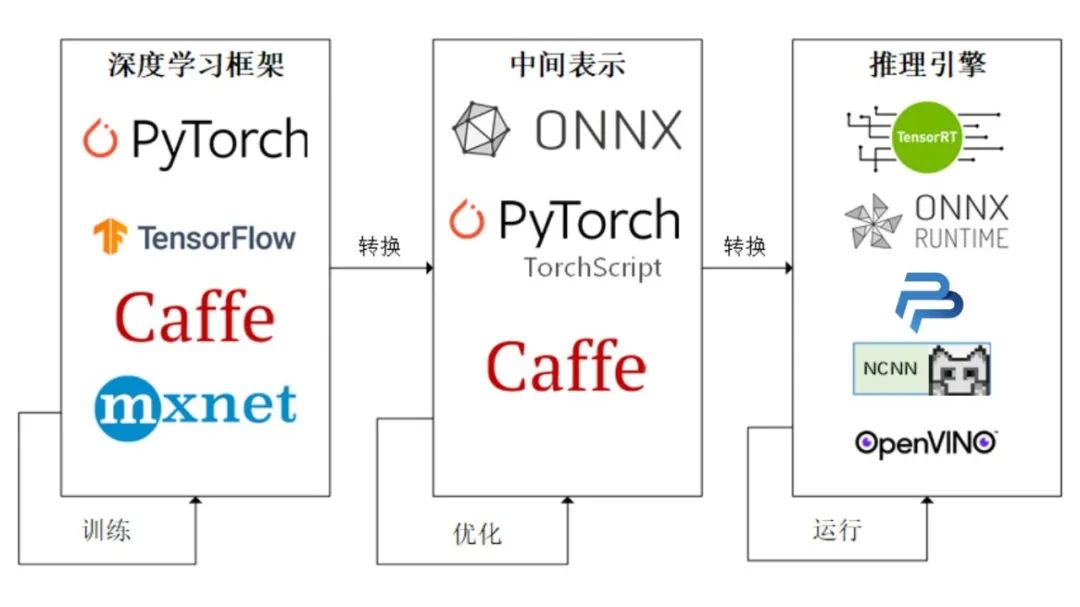
PyTorch生态与部署 1.PyTorch生态简介 https://datawhalechina.github.io/thorough-pytorch/第八章/index.html
PyTorch的强大很大程度上取决于它的生态。
(1)torchvision
torchvision.datasets * 包含了一些我们在计算机视觉中常见的数据集
torchvision.models *
提供一些预训练模型
torchvision.tramsforms * 用于数据增强和处理
torchvision.io
视频、图片和文件的 IO 操作(读取、写入、编解码)
torchvision.ops 提供了许多计算机视觉的特定操作
torchvision.utils
提供了一些可视化的方法
(2)PyTorchVideo PytorchVideo 提供了加速视频理解研究所需的模块化和高效的API。它还支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换,最重要的是,PytorchVideo也提供了model zoo,使得人们可以使用各种先进的预训练视频模型及其评判基准。
基于 PyTorch,高质量model zoo,支持主流数据集及预处理,模块化设计,支持多模态,移动端部署优化
(3)torchtext
数据处理工具 torchtext.data.functional、torchtext.data.utils
数据集 torchtext.data.datasets
词表工具 torchtext.vocab
评测指标 torchtext.metrics
构建数据集
①构建Field
1 2 3 tokenize = lambda x: x.split() TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=200) LABEL = data.Field(sequential=False, use_vocab=False)
②进一步构建dataset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from torchtext import data def get_dataset(csv_data, text_field, label_field, test=False): fields = [("id", None), # we won't be needing the id, so we pass in None as the field ("comment_text", text_field), ("toxic", label_field)] examples = [] if test: # 如果为测试集,则不加载label for text in tqdm(csv_data['comment_text']): examples.append(data.Example.fromlist([None, text, None], fields)) else: for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])): examples.append(data.Example.fromlist([None, text, label], fields)) return examples, fields
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 train_data = pd.read_csv('train_toxic_comments.csv') valid_data = pd.read_csv('valid_toxic_comments.csv') test_data = pd.read_csv("test_toxic_comments.csv") TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True) LABEL = data.Field(sequential=False, use_vocab=False) # 得到构建Dataset所需的examples和fields train_examples, train_fields = get_dataset(train_data, TEXT, LABEL) valid_examples, valid_fields = get_dataset(valid_data, TEXT, LABEL) test_examples, test_fields = get_dataset(test_data, TEXT, None, test=True) # 构建Dataset数据集 train = data.Dataset(train_examples, train_fields) valid = data.Dataset(valid_examples, valid_fields) test = data.Dataset(test_examples, test_fields) # 检查keys是否正确 print(train[0].__dict__.keys()) print(test[0].__dict__.keys()) # 抽查内容是否正确 print(train[0].comment_text)
构建词语到向量(或数字)的映射关系
在torchtext中可以使用Field自带的build_vocab函数完成词汇表构建。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from torchtext.data import Iterator, BucketIterator # 若只针对训练集构造迭代器 # train_iter = data.BucketIterator(dataset=train, batch_size=8, shuffle=True, sort_within_batch=False, repeat=False) # 同时对训练集和验证集进行迭代器的构建 train_iter, val_iter = BucketIterator.splits( (train, valid), # 构建数据集所需的数据集 batch_sizes=(8, 8), device=-1, # 如果使用gpu,此处将-1更换为GPU的编号 sort_key=lambda x: len(x.comment_text), # the BucketIterator needs to be told what function it should use to group the data. sort_within_batch=False ) test_iter = Iterator(test, batch_size=8, device=-1, sort=False, sort_within_batch=False)
2.PyTorch模型部署 https://datawhalechina.github.io/thorough-pytorch/第九章/index.html
ONNX (1)ONNX简介 ①ONNX
通过定义一组与环境和平台无关的标准格式,使AI模型可以在不同框架和环境下交互使用。
使用不同框架训练的模型,转化为ONNX格式后,可以很容易的部署在兼容ONNX的运行环境中。
②ONNX Runtime
跨平台机器学习推理加速器,可直接读取 .onnx 格式的文件。
③安装
ONNX和ONNX Runtime的适配关系:https://github.com/microsoft/onnxruntime/blob/master/docs/Versioning.md
使用GPU进行推理时,需要卸载onnxruntime,再安装onnxruntime-gpu,同时还需考虑ONNX Runtime与CUDA之间的适配关系,参考链接
1 2 3 4 5 6 7 # 激活虚拟环境 conda activate env_name # env_name换成环境名称 # 安装onnx pip install onnx # 安装onnx runtime pip install onnxruntime # 使用CPU进行推理 # pip install onnxruntime-gpu # 使用GPU进行推理
(2)模型导出为ONNX 使用torch.onnx.export()把模型转换成 ONNX 格式的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torch.onnx # 转换的onnx格式的名称,文件后缀需为.onnx onnx_file_name = "xxxxxx.onnx" # 我们需要转换的模型,将torch_model设置为自己的模型 model = torch_model # 加载权重,将model.pth转换为自己的模型权重 # 如果模型的权重是使用多卡训练出来,我们需要去除权重中多的module. 具体操作可以见5.4节 model = model.load_state_dict(torch.load("model.pth")) # 导出模型前,必须调用model.eval()或者model.train(False) model.eval() # dummy_input就是一个输入的实例,仅提供输入shape、type等信息 batch_size = 1 # 随机的取值,当设置dynamic_axes后影响不大 dummy_input = torch.randn(batch_size, 1, 224, 224, requires_grad=True) # 这组输入对应的模型输出 output = model(dummy_input) # 导出模型(需确保我们的模型处在推理模式) torch.onnx.export(model, # 模型的名称 dummy_input, # 一组实例化输入 onnx_file_name, # 文件保存路径/名称 export_params=True, # 如果指定为True或默认, 参数也会被导出. 如果你要导出一个没训练过的就设为 False. opset_version=10, # ONNX 算子集的版本,当前已更新到15 do_constant_folding=True, # 是否执行常量折叠优化 input_names = ['input'], # 输入模型的张量的名称 output_names = ['output'], # 输出模型的张量的名称 # dynamic_axes将batch_size的维度指定为动态, # 后续进行推理的数据可以与导出的dummy_input的batch_size不同 dynamic_axes={'input' : {0 : 'batch_size'}, 'output' : {0 : 'batch_size'}})
(3)可用性检查 1 2 3 4 5 6 7 8 9 10 import onnx # 我们可以使用异常处理的方法进行检验 try: # 当我们的模型不可用时,将会报出异常 onnx.checker.check_model(self.onnx_model) except onnx.checker.ValidationError as e: print("The model is invalid: %s"%e) else: # 模型可用时,将不会报出异常,并会输出“The model is valid!” print("The model is valid!")
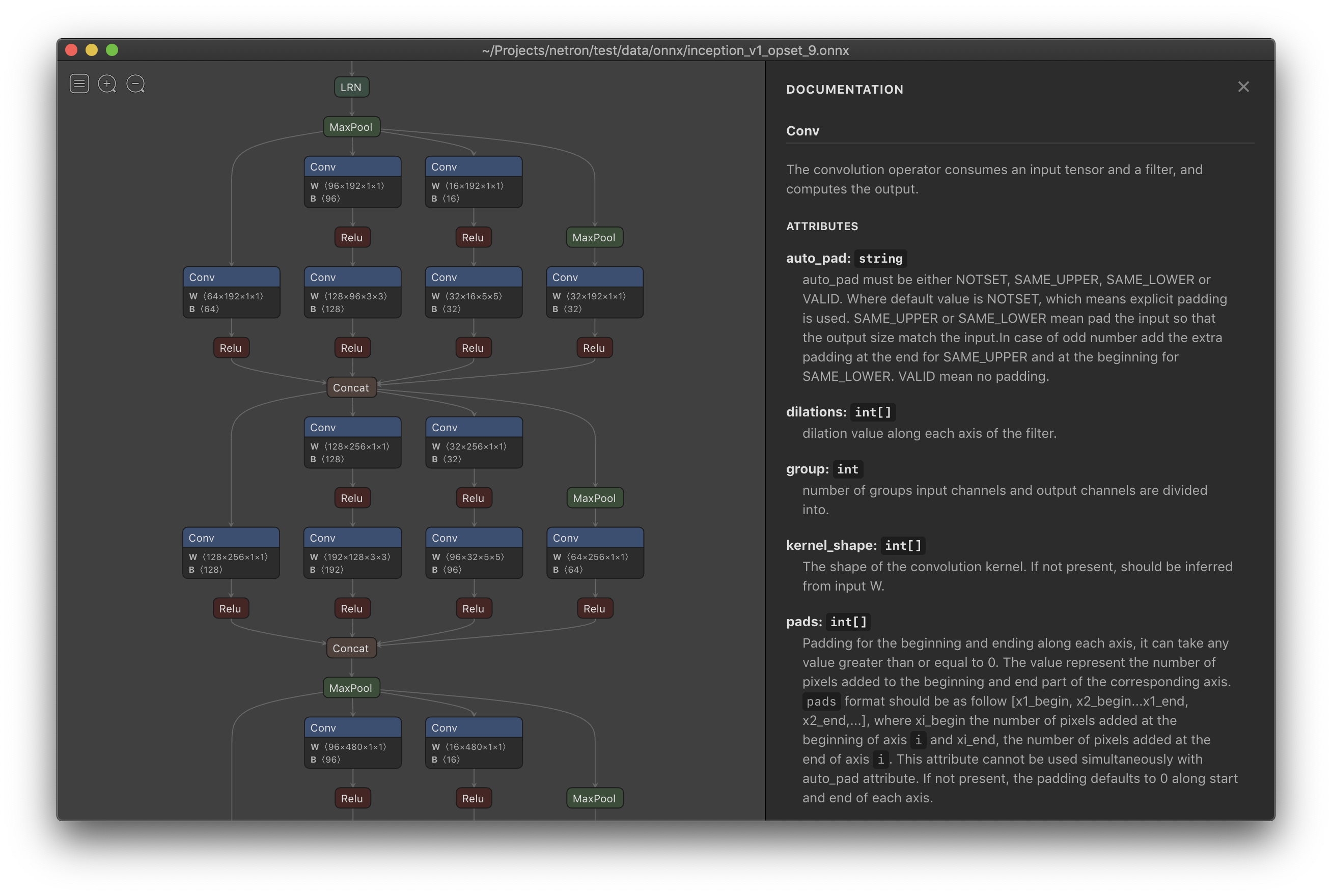
(4)可视化 Netron