PyTorch模型定义 DataWhale:https://datawhalechina.github.io/thorough-pytorch/
一、模型定义
Module 类是 torch.nn 模块里提供的一个模型构造类 (nn.Module),是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型;PyTorch模型定义应包括两个主要部分:各个部分的初始化(__init__);数据流向定义(forward)
基于nn.Module,我们可以通过Sequential,ModuleList和ModuleDict三种方式定义PyTorch模型。
1. Sequential 可更加简单地定义前向计算为简单串联各层的模型。
接收子模块或其有序字典作为参数逐一添加作为实例以进行前向计算。
灵活性差,不适合加入外部输入。
1 2 3 4 5 6 import torch.nn as nn net = nn.Sequential( nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10), ) #直接排列
1 2 3 4 5 6 7 import collections import torch.nn as nn net2 = nn.Sequential(collections.OrderedDict([ ('fc1', nn.Linear(784, 256)), ('relu1', nn.ReLU()), ('fc2', nn.Linear(256, 10)) ])) #使用OrderedDict
2.ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入
可以进行append和extend操作
需要经过forward函数指定各个层的先后顺序
1 2 3 net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()]) net.append(nn.Linear(256, 10)) # # 类似List的append操作 print(net[-1]) # 类似List的索引访问
3.ModuleDict 和ModuleList类似,只是ModuleDict能够更方便地为神经网络的层添加名称
1 2 3 4 5 6 7 net = nn.ModuleDict({ 'linear': nn.Linear(784, 256), 'act': nn.ReLU(), }) net['output'] = nn.Linear(256, 10) # 添加 print(net['linear']) # 访问 print(net.output)
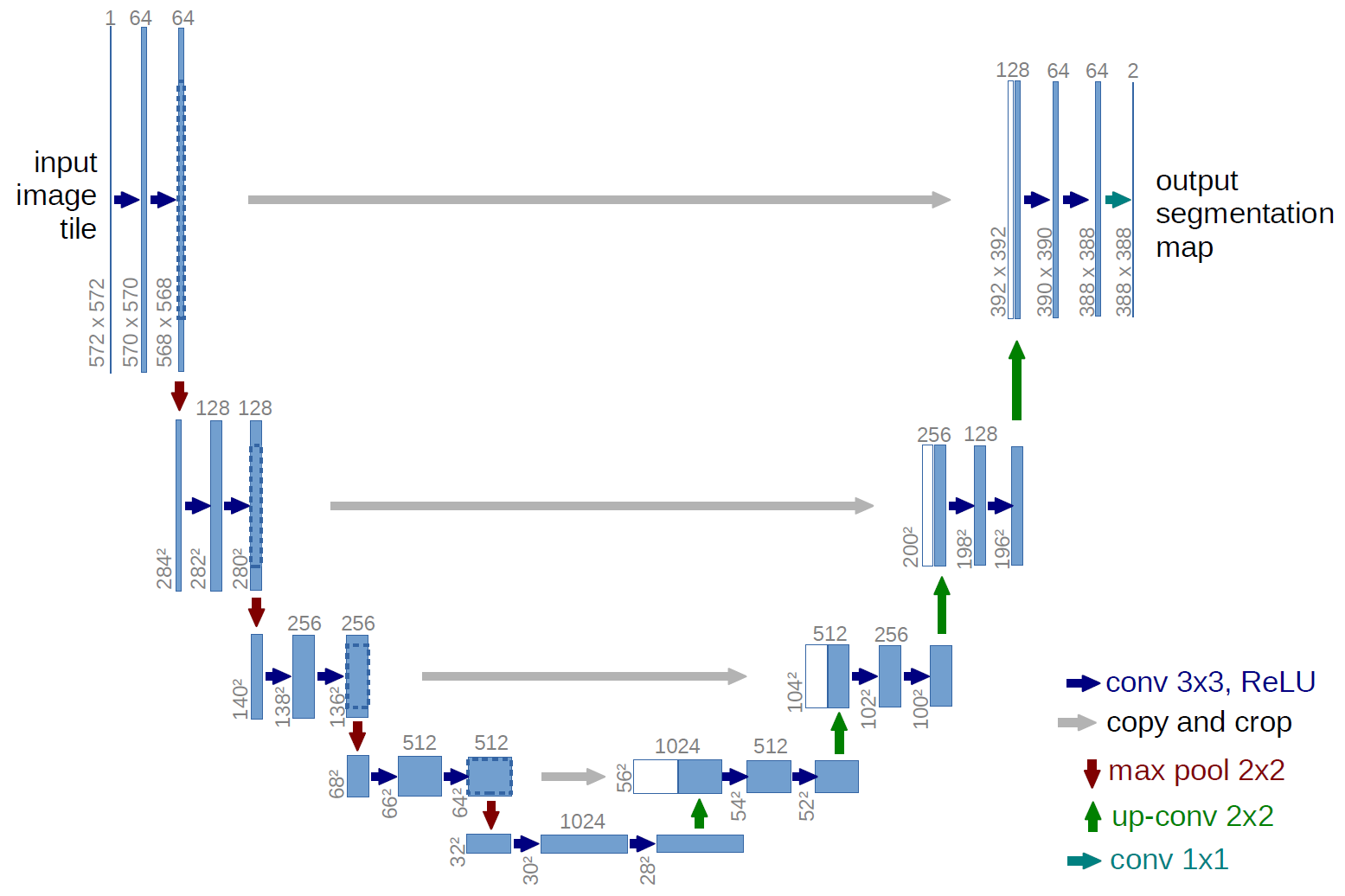
二、利用模型块快速搭建复杂网络 以U-Net为例
1.U-Net 通过残差连接结构解决了模型学习中的退化问题,使得神经网络的深度能够不断扩展。
1)梯度消失问题
我们发现很深的网络层,由于参数初始化一般更靠近0,这样在训练的过程中更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。
2)网络退化问题
举个例子,假设已经有了一个最优化的网络结构,是18层。当我们设计网络结构的时候,我们并不知道具体多少层次的网络时最优化的网络结构,假设设计了34层网络结构。那么多出来的16层其实是冗余的,我们希望训练网络的过程中,模型能够自己将这16层冗余层训练为恒等映射,也就是经过这层时的输入与输出完全一样。但是往往模型很难将这16层恒等映射的参数学习正确,那么就不如最优化的18层网络结构的性能,这就是随着网络深度增加,模型会产生退化现象。它不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
组成U-Net的模型块主要有如下几个部分:
1 2 3 import torch import torch.nn as nn import torch.nn.functional as F
1)每个子块内部的两次卷积(Double Convolution)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class DoubleConv(nn.Module): """(convolution => [BN] => ReLU) * 2""" def __init__(self, in_channels, out_channels, mid_channels=None): super().__init__() if not mid_channels: mid_channels = out_channels self.double_conv = nn.Sequential( nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(mid_channels), nn.ReLU(inplace=True), nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ) def forward(self, x): return self.double_conv(x)
2)左侧模型块之间的下采样连接,即最大池化(Max pooling)
1 2 3 4 5 6 7 8 9 10 11 12 class Down(nn.Module): """Downscaling with maxpool then double conv""" def __init__(self, in_channels, out_channels): super().__init__() self.maxpool_conv = nn.Sequential( nn.MaxPool2d(2), DoubleConv(in_channels, out_channels) ) def forward(self, x): return self.maxpool_conv(x)
3)右侧模型块之间的上采样连接(Up sampling)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Up(nn.Module): """Upscaling then double conv""" def __init__(self, in_channels, out_channels, bilinear=False): super().__init__() # if bilinear, use the normal convolutions to reduce the number of channels if bilinear: self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) self.conv = DoubleConv(in_channels, out_channels, in_channels // 2) else: self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) self.conv = DoubleConv(in_channels, out_channels) def forward(self, x1, x2): x1 = self.up(x1) # input is CHW diffY = x2.size()[2] - x1.size()[2] diffX = x2.size()[3] - x1.size()[3] x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2]) # if you have padding issues, see # https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a # https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd x = torch.cat([x2, x1], dim=1) return self.conv(x)
4)输出层的处理
1 2 3 4 5 6 7 class OutConv(nn.Module): def __init__(self, in_channels, out_channels): super(OutConv, self).__init__() self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1) def forward(self, x): return self.conv(x)
三、修改模型 我们有时需要对模型结构进行必要的修改。
1.修改模型层 可修改输出节点数、层数等。
2.添加外部输入 将原模型添加输入位置前的部分作为一个整体,同时在forward中定义好原模型不变的部分、添加的输入和后续层之间的连接关系,从而完成模型的修改。
3.添加额外输出 输出模型某一中间层的结果,以施加额外的监督,获得更好的中间层结果。基本的思路是修改模型定义中forward函数的return变量。
四、PyTorch模型保存与读取 一个PyTorch模型主要包含两个部分:模型结构和权重。
模型是继承nn.Module的类,权重的数据结构是一个字典(key是层名,value是权重向量)。
两种形式:存储整个模型(包括结构和权重),和只存储模型权重。
1 2 3 4 # 保存整个模型 torch.save(model, save_dir) # 保存模型权重 torch.save(model.state_dict, save_dir)
关于单卡和多卡的问题:(DataWhale在线文档)https://datawhalechina.github.io/thorough-pytorch/第五章/5.4%20PyTorh模型保存与读取.html