
吃瓜教程-P5
1.前言
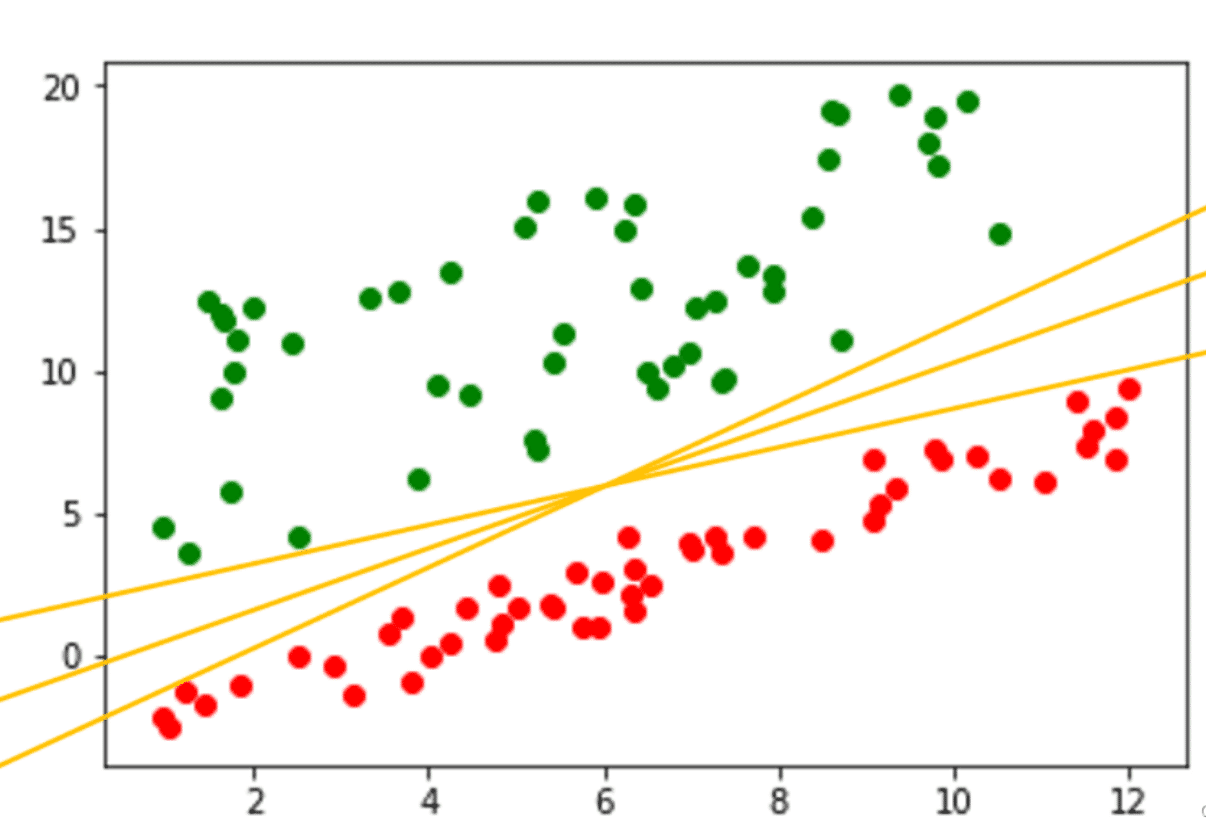
如上图所示,我们希望找到一个边界使两类数据分开,显然可以找到许多符合条件的边界,但对于看不见的点或者验证数据集,就不一定能很好地分隔两类。支持向量机(SVM)就是为了寻找最佳的决策边界,既能将两类很好的分隔开来,而且还保持了两个类的最极端点之间的最宽距离。
挖坑:如果无法找到那个边界呢?

2.什么是支持向量机
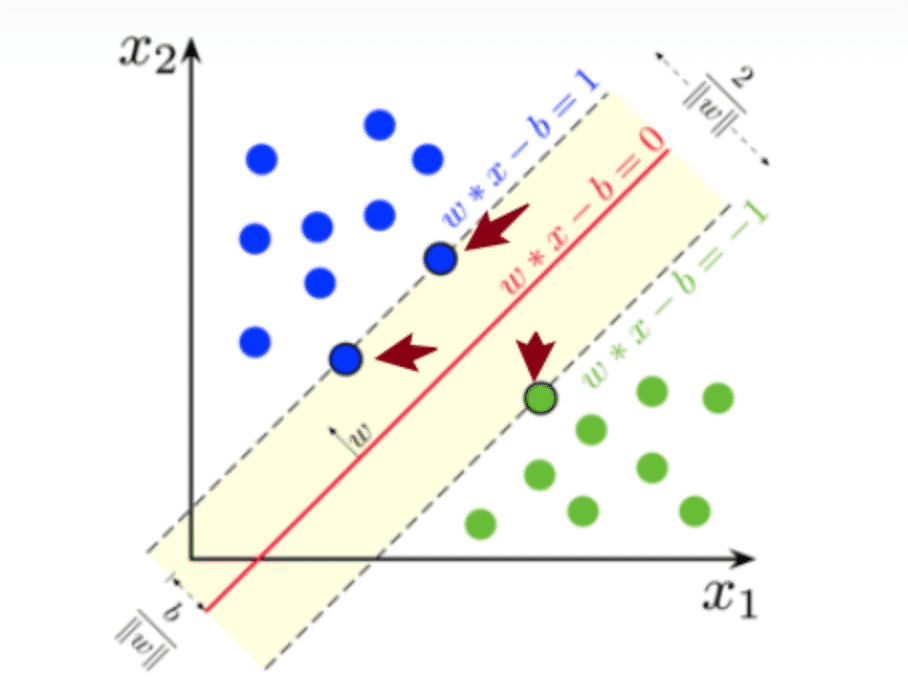
支持向量机(SVM)本质上是尝试拟合两个类别之间最宽的间距,使得图1中的两条虚线之间的距离最大,那么分布在虚线上的点就叫支持向量。也可以说,支持向量决定了虚线的位置,非支持向量,即图中不在虚线上的点不会影响决策边界的位置。
原理
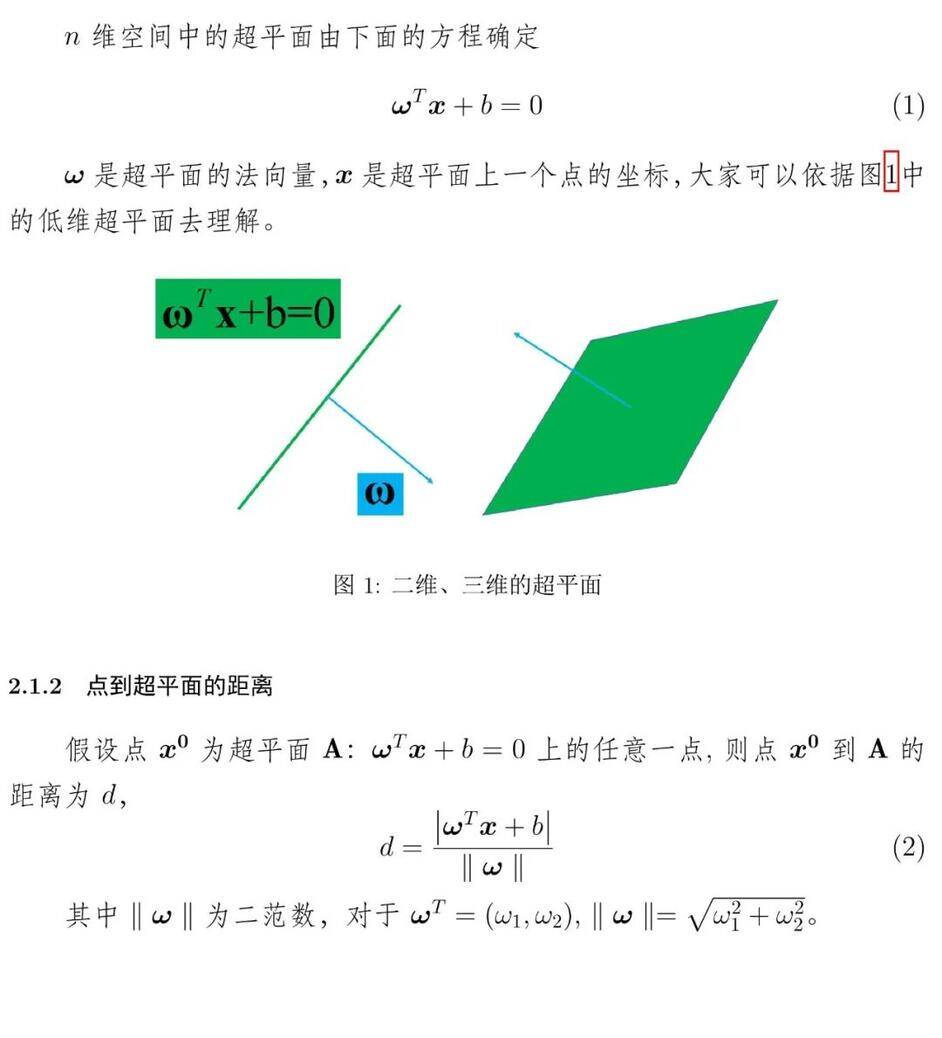
根据最大几何间隔选择最佳超平面

3.核函数
填坑
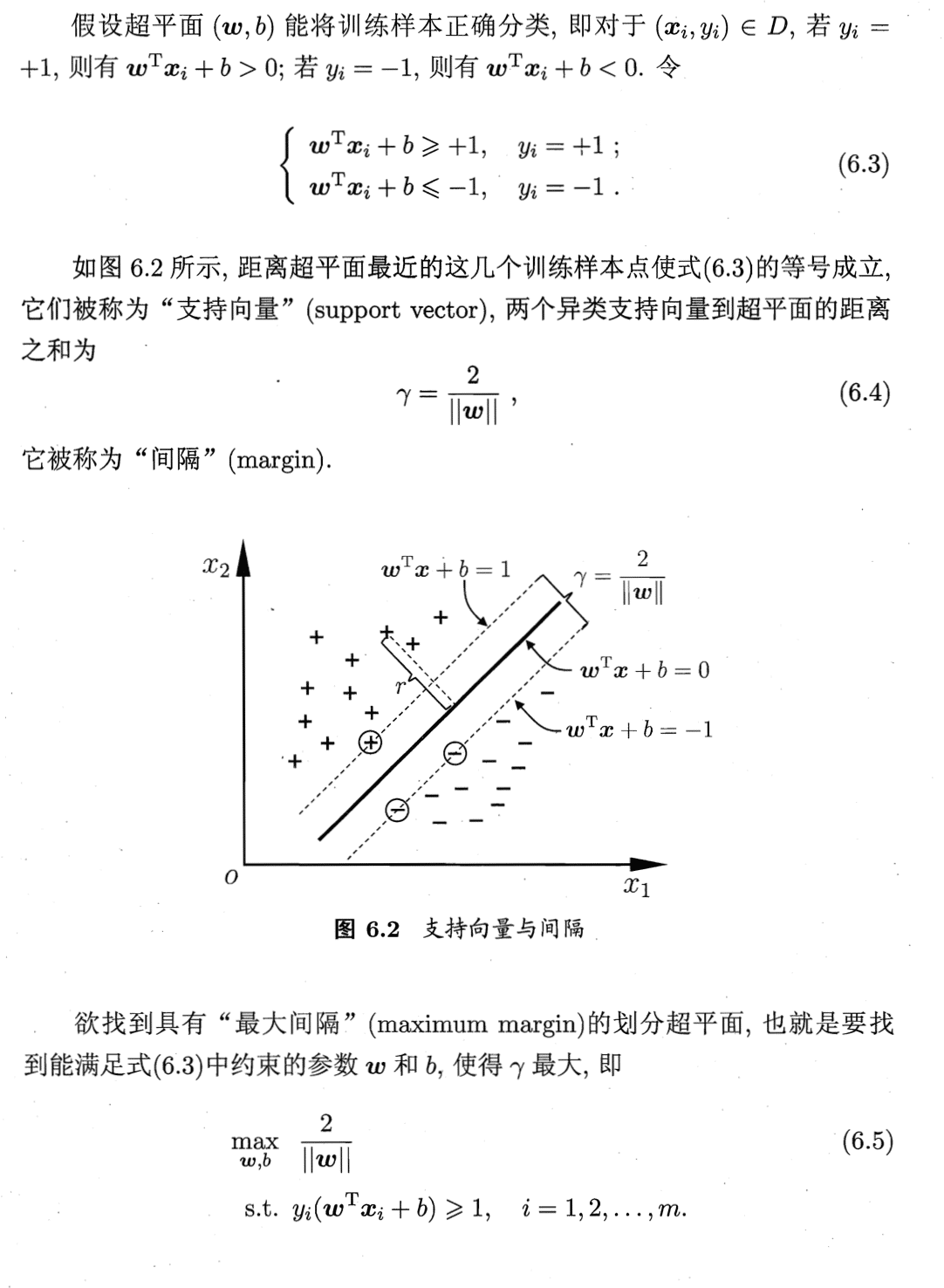
在本章前面的讨论中,我们假设训练样本是线性可分的,即存在一个划分超平面能将训练样本正确分类.然而在现实任务中,原始样本空间内也许并不存在一个能正确划分两类样本的超平面。对这样的问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分.
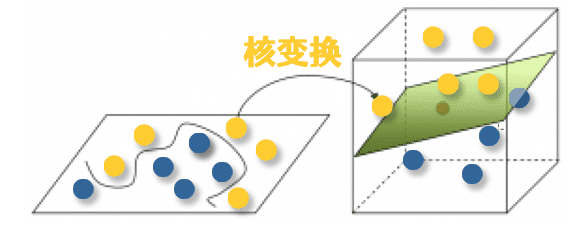
3.1直接计算

3.2通过设想函数避开直接计算

3.3核函数
上面的k(~,~)即为核函数。
若已知合适映射的具体形式,则可写出核函数,但在现实任务中我们通常不知道。
“核函数选择”成为支持向量机的最大变数,若核函数选择不合适,则意味着将样本映射到了一个不合适的特征空间,很可能导致性能不佳。
常用核函数

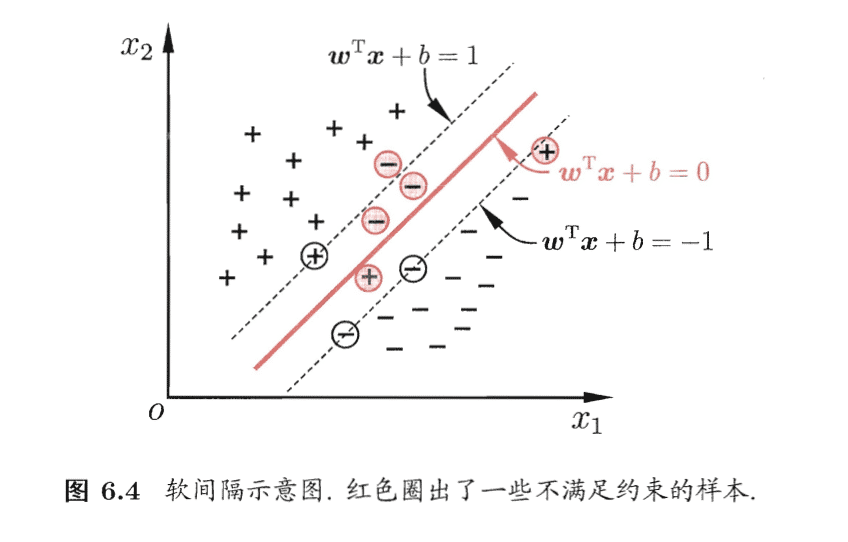
4.软间隔
对于线性不可分系统,无法找到合适的核函数。
缓解该问题的一个办法是允许支持向量机在一些样本上出错,即允许某些样本不满足约束。为此引入 “软间隔”(soft margin)的概念。

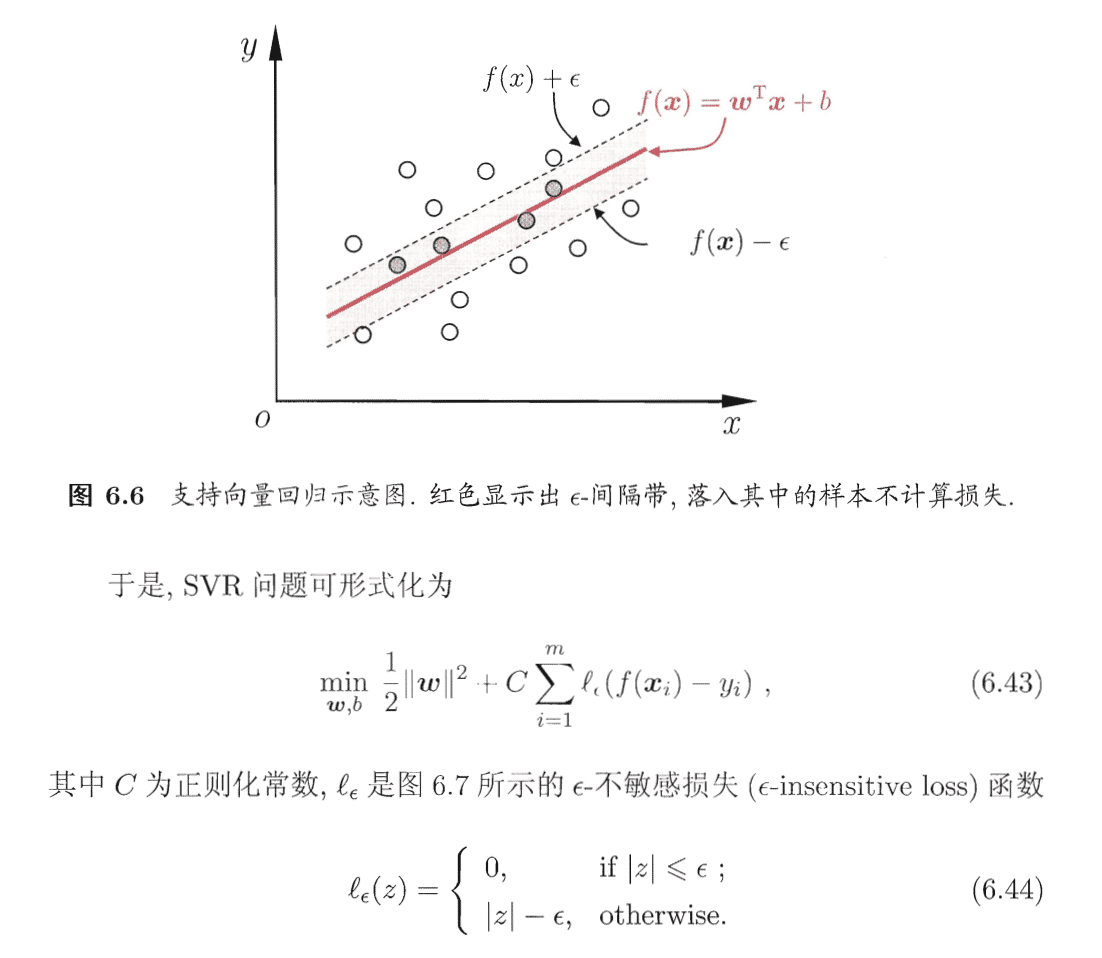
5.支持向量回归
支持向量回归(SVR)假设能容忍 f(x) 与 y 之间最多有ε的偏差,即仅当 f(x) 与 y 之间的差别绝对值大于ε时才计算损失。这相当于以 f(x) 为中心,构建了一个宽度为2ε的间隔带,若训练样本落入此间隔带,则认为被预测正确的。
6.核方法

人们发展出一系列基于核函数的学习方法,统称为 “核方法”(kernel methods).
通过核化来对其进行非线性拓展,从而得到”核线性判别分析”(KLDA).

使用线性判别分析求解方法即可得到α ,进而可由式(6.64)得到投影函数h(x).
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 云中漫步!

