百度Apollo自动驾驶仿真平台9.0版本Perception模块相关内容
基于官方教程https://apollo.baidu.com/community/article/1186,根据实际使用增改部分内容。
1 Apollo Perception环境配置
1.1 安装基础软件
1.1.1 安装Linux - Ubuntu
Ubuntu系统安装完成请更新相关软件:
1 | sudo apt-get update |
1 | sudo apt-get upgrade |
1.1.2 安装 Docker Engine
Apollo 依赖于 Docker 19.03+。安装 Docker 引擎,您可以根据官方文档进行安装:
1 | wget http://apollo-pkg-beta.bj.bcebos.com/docker_install.shbash docker_install.sh |
1 | bash docker_install.sh |
注:1.1.1和1.1.2步骤安装过无需重复安装。
1.1.3 安装驱动
显卡驱动和CUDA版本兼容性,由于nvidia的硬件更新的很快,因此会遇到显卡驱动和CUDA版本不兼容的情况,以下为我们测试的畅通链路。
| 显卡系列 | 测试显卡 | 驱动版本 | 最低支持驱动版本 | cuda版本 |
|---|---|---|---|---|
| GeForce 10 Series | GeForce GTX 1080 | nvidia-driver-470.160.03 | nvidia-driver-391.35 | CUDA Version :11.4 |
| GeForce RTX 20 Series | GeForce RTX 2070 SUPER | nvidia-driver-470.63.01 | nvidia-driver-456.38 | CUDA Version :11.4 |
| GeForce RTX 30 Series | GeForce RTX 3090 | nvidia-driver-515.86.01 | nvidia-driver-460.89 | CUDA Version :11.6 |
| GeForce RTX 3060 | nvidia-driver-470.63.01 | nvidia-driver-460.89 | CUDA Version :11.4 | |
| Tesla V-Series | Tesla V100 | nvidia-driver-418.67 | nvidia-driver-410.129 | CUDA Version :10.1 |
| AMD | MI100 dGPU | ROCm™ 3.10 driver |
1.1.3.1 安装显卡驱动
10、20、30系列显卡推荐使用470.63.01版本,下载链接470.63.01显卡驱动
(实际使用时显卡驱动版本高于推荐也可正常使用,因此在安装系统时已将驱动安装好的话,则不用安装,再次安装会提示已安装驱动无法再次安装):
1 | #使用该命令查看是否安装显卡,若出现下述“驱动检查”所示图内容,则已安装显卡驱动,否则执行下面指令安装 |
下载之后,找到相应的文件夹打开终端输入指令:
1 | sudo chmod 777 NVIDIA-Linux-x86_64-470.63.01.runsudo ./NVIDIA-Linux-x86_64-470.63.01.run |
驱动检查
1 | nvidia-smi |
注:如若出现以下情况,则说明没有下载显卡驱动https://apollo.baidu.com/community/article/1181
注:本教程只适用于ubuntu系统,虚拟机无法安装显卡驱动
1.1.3.2 安装nvida-docker
为了在容器内获得 GPU 支持,在安装完 docker 后需要安装 NVIDIA Container Toolkit。 运行以下指令安装 NVIDIA Container Toolkit:(实际使用时会出现报错:无法定位软件包 nvidia-docker2)
1 | distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get -y update sudo apt-get install -y nvidia-docker2 |
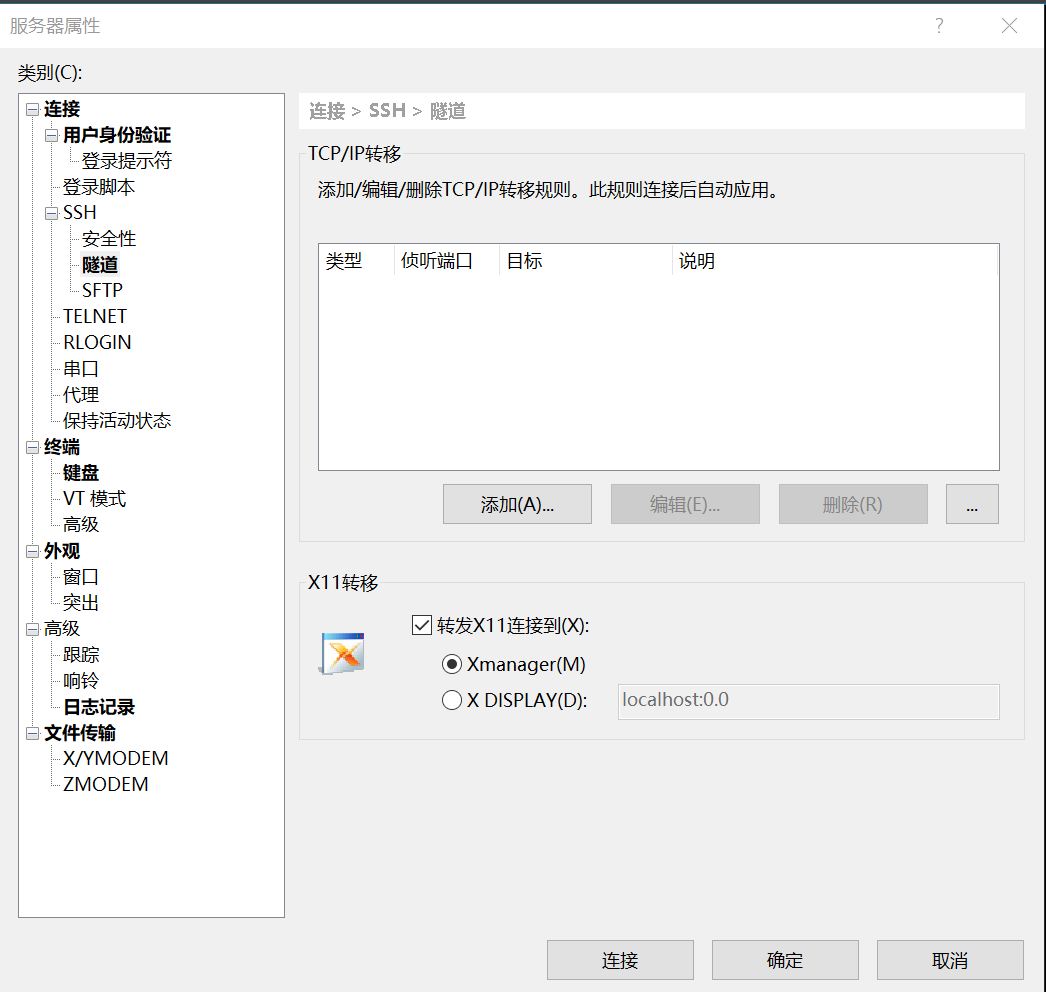
注:如果上面方法报错,则使用官方方法nvida-docker官方教程,执行下面图片中的两条指令:

1.2 安装 Apollo 环境管理工具
1.2.1 基础环境准备
1 | # 添加访问认证 |
1.2.2 安装 aem工具
如果没有安装过apollo 8.0aem,使用以下命令直接安装:
1 | sudo apt install apollo-neo-env-manager-dev |
安装成功后,可以使用以下查看安装是否成功,出现下图所示即为成功:
1 | aem -h |

1.3 下载 Perception工程
1.3.1 下载工程代码
1 | git clone https://github.com/ApolloAuto/application-perception |
注:如果出现⽆法访问等问题,可使⽤以下⽅法:
1 | git clone [https://gitee.com/ApolloAuto/application-perception](https://gitee.com/ApolloAuto/application-perception) |
1.3.2 进入工程目录
1 | cd application-perception |
1 | #检查目录,只是看一下文件结构,并未有数据操作,如下显示"9.0.0-alpha2-r31"即为正确 |
注:如若显示“9.0.0-alpha2-r29”:
1 | #请使用: |
或手动更改.workspace.json文件的9.0.0-alpha2-r29为9.0.0-alpha2-r31
再使用cat .workspace.json 指令查看是否已更改
1.4 调试perception工程
1.4.1 进入Docker环境
1 | # 拉取并启动docker容器 |
注:在输入aem start后终端应为下图所示

若仍然出现下图所示warning,则1.1.3.2 安装nvida-docker失败

检查buildtool版本
1 | buildtool -v |

注:如若buildtool版本与上图不一致,即以9.0.0-alpha开头的版本,请使用以下指令更新:
1 | sudo apt update && sudo apt install --only-upgrade apollo-neo-buildtool |
升级aem工具
1 | sudo apt install apollo-neo-env-manager-dev |
安装依赖包
会拉取安装core目录下的cyberfile.xml里面所有的依赖包
1 | buildtool build --gpu |
注:该工程中只有感知功能,如若想添加PnC(planning规划)功能请参考如下链接(可选)
请参考文章中的1.1.5升级CCF- BDCI赛事复赛工程https://apollo.baidu.com/community/article/1180
另外:安装的planning等模块的源码会保存到工程文件的modules文件夹中,如果安装后并未出现,可参考application-perception/core/cyberfile.xml文件中的内容进行安装,具体使用如下:
1 | buildtool install xxx |
其中xxx为想要安装的模块名称,例如要安装planning的源码,可查阅cyberfile.xml文件,可知其repo_name为”planning”:

则安装命令相应为:
1 | buildtool install planning |
执行后在application-perception/modules文件夹内会出现planning源码文件夹:

1.4.2 设置车型参数
本次赛事用的是apolloscape数据集,车型参数设置为apolloscape参数。
1 | aem profile use apolloscape |
1.4.3 启动Dreamview+
1 | aem bootstrap start --plus |
plus参数指的是启动dreamview+。
1.4.4 下载安装感知模型
安装amodel模型管理工具:
1 | wget https://apollo-pkg-beta.cdn.bcebos.com/perception/amodel-0.2.0.tar.gz |
导入环境变量:
1 | export PATH=~/.local/bin/:$PATH |
安装感知模型:
1 | sudo ~/.local/bin/amodel install center_point_paddle |
安装完后使用命令查看安装的模型:
1 | amodel list |
1.4.5 启动lidar感知程序,播包调试(该步骤用于播放record,安装时不用执行)
启动lidar感知有两个方法,以下两个方法选择一个。
1.4.5.1 Dreamview+ 启动
在1.4.3启动Dreamview后,点击左侧Mode Settings按钮,Mode选择Perception:

启动Transform、Lidar感知模块:

1.4.5.2 命令行启动(一般用Dreamview+ 启动即可)
启动transform:
1 | cyber_launch start /apollo/modules/transform/launch/static_transform.launch |
启动lidar感知:
1 | cyber_launch start /apollo/modules/perception/lidar_output/launch/lidar_output.launch |
1.4.5.3 播包调试感知
在Dreamview观察感知情况。record包的生产参考下面的数据准备部分:
1 | # xxx.record是具体record的名称 |
2 数据准备
2.1 数据下载
训练集、测试集和脚本代码中分别有readme说明。
一共需要下载下面三个文件,其中前两个大小都在13G左右,需要有足够空间。
点击下表中的链接会在浏览器直接创建下载任务,不过速度很慢。
推荐将下方链接复制,然后在windows中使用迅雷新建下载任务,填入复制的链接下载,或者找我拷贝。

注注注:官方还推出了使用百度ai studio进行训练的教程,如果内存不足,则不要下载,可以参考此链接:https://apollo.baidu.com/community/article/1184
(分数榜单使用的数据集) |
| 3 | 脚本代码 | https://apollo-records.bj.bcebos.com/perception/apolloscape/apolloscape_scripts.zip?authorization=bce-auth-v1/0824ae9513f643518e120667fc2a6d50/2023-11-13T11%3A32%3A35Z/2592000/host/e662b3c0219eeaa374ecbec0e024c9f71e1b7925de9d06a79c6506b035f466f6 | 将ApolloScape数据集转换为KITTI数据集的脚本
将ApolloScape数据转换为record的脚本 |
2.2 adataset环境配置
adataset用于将apolloscape数据转化为apollo record格式,方便做端到端感知调试。
1 | # 在application-perception目录下进入到容器内。如果已经在容器内,则不需要执行。 |
安装adataset:
1 | # 更新pip源 |
2.3 数据转化
下载的三个文件为三个压缩包,各自包含内容如下:



我们可以将压缩包里的三个文件提取到同一个文件夹 apolloDataSet 内:

在脚本代码scripts文件夹内中有apolloscape_to_records.py和apolloscape_to_kitti.py,即下面命令所用到的两个程序。
同时我们需要提前创建两个空文件夹train_records,kitti,用于存放下面转换的数据:

2.3.1 使用apolloscape_to_records.py将apolloscape转化成apollo records数据(需要在 apolloDataSet 文件夹打开终端):
1 | # -d表示apolloscape数据集。用a就好; |
注:如果报错ModuleNotFoundError: No module named ‘yaml’,执行下面命令安装后重新运行上面代码即可:
1 | pip install pyyaml |
2.3.2 Python2环境安装
(1)安装miniconda(anaconda的轻量版)
官网:https://docs.conda.io/projects/miniconda/en/latest/miniconda-install.html
或者参考我的教程:https://yang-makabaka.github.io/posts/4120ac2f.html
(2)使用conda创建环境
- 创建python2环境:
1 | conda create -n python2 python=2.7 |
- 切换到python2环境:
1 | conda activate python2 |
安装pypcd和numpy:
1
2
3conda install numpy
pip install pypcd然后就可以使用下面命令将apolloscape数据集转化成kitti格式。
2.3.3 使用apolloscape_to_kitti.py将apolloscape数据转化kitti格式,用于训练centerpoint模型(需要在 apolloDataSet 文件夹打开终端,且进入上面创建的环境python2):
1 | #注:此步骤可在本地环境操作,不需要在容器中。本地需要具备pypcd库、numpy库和python2环境。 |